부스트캠프 AI Tech 6주차 주간 학습 정리
Day 1
- 학습 강의 : Part 1 - Bag of Words & Word Embedding 1강, 2강
- 과제 : [필수과제 1] Data Preprocessing
1. 강의 복습
NLP
1강 : Intro to NLP, Bag-of-Words
- NLP는 Natural Language Understanding(NLU)와 Natural Language Generating(NLG)의 task로 구성되어 있다.
- Natural Language processing
- Low-level parsing
- Tokenization
- Stemming(어미가 달라지더라도 그 변화를 없애고 어근을 추출하는 것)
- Word and phrase level
- Named entitiy recognition(NER) : 여러 단어로 이루어져있는 고유 명사 ex) New York Times
- Part-of-speecn(POS) tagging : 문장 내의 품사나 성분 등을 알아내는 작업
- Sentence Level
- Sentiment analysis : 문장의 긍정, 부정을 분석
- Machine translation
- Multi-sentence and paragraph level
- Entailment prediction : 두 문장 간의 논리적인 내포나 모순 관계를 예측
- Question answering
- Dialog systems : 대화할 수 있는 시스템 ex) 챗봇
- Summarization : 문서를 요약
- Low-level parsing
- Text mining
- Document clustering
- computation social science : 사회과학적인 Insight
- Information retrieval
- 추천 시스템
- Bag-of-Words Representation
- Step 1. 문장에서 단어들을 모아서 Vocabulary를 구축
- Step 2. 각각의 단어들을 one-hot vector로 인코딩한다.

- 주어진 단어들 사이의 유클리드 거리는 모두 $\sqrt2$이다.
- consine similarity(내적값)는 모두 0이다.
- 각 단어들의 one-hot vector를 더함으로써 문장이나 문서를 나타낼 수 있다.

- NaiveBayes Classifier
- Conditional independence assumption에 의해 다음 식이 성립
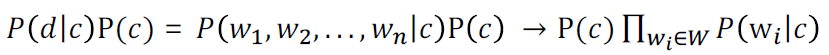
- Conditional independence assumption에 의해 다음 식이 성립
2강 : Word Embedding
- Word Embedding이란 문장 속의 단어들을 특정 차원에서의 벡터로 변환해주는 것이다.
- 의미가 비슷한 단어는 가까운 거리를, 의미가 다른 단어는 먼 거리를 가지는 좌표값으로 변환된다.
- Word Embedding을 학습하는 방법에는 Word2Vec, GloVe가 있다.
- Word2Vec
- 같은 문장에서 나타난 인접한 단어들 간에는 관련성이 있다는 가정을 사용
- 한 단어가 주변에 등장하는 단어들을 통해 그 의미를 추론할 수 있다.

- cat이란 단어가 주어졌을 때 그 단어와의 연관성을 확률적으로 나타내면 위와 같다.
- Word2Vec Algorithm Works
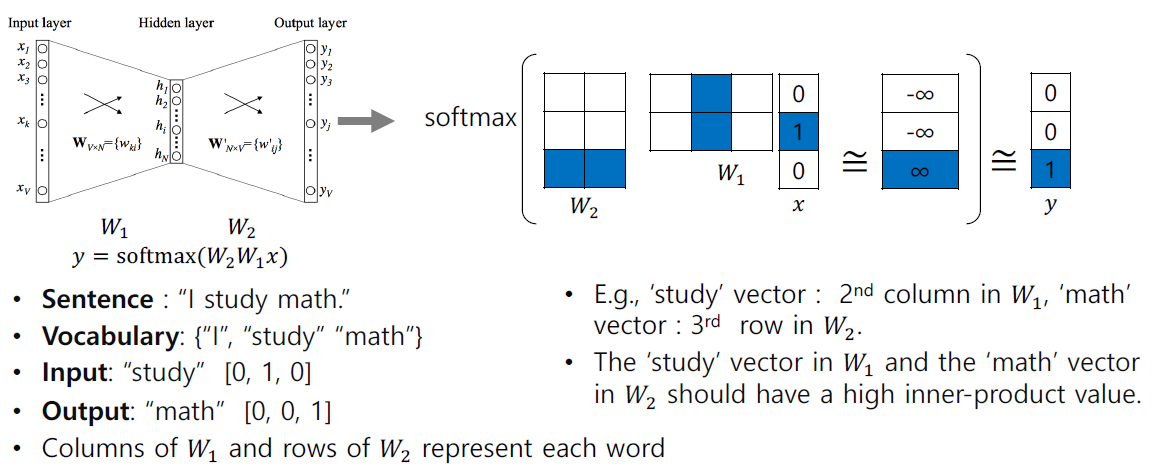
- window size에 따라 학습 데이터가 결정된다. window 사이즈가 3이라고 하면
(I, study), (study, I), (study, math), (math, study)와 같이 구성될 수 있다. (study, math)로 예를 들면 x에[0, 1, 0]vector가 들어가고 Ground Truth는[0, 0, 1]vector가 나온 것을 확인할 수 있다. Softmax를 통해 나온 확률분포 vector와 GT로 주어지는 vector 간의 거리가 가까워지는 방향으로 학습이 진행된다.- 단어가 Embedding된 one hot vector와 선형변환 Metrix($W_1$)이 곱해지는 것을 embedding layer라 한다.
- one hot vector와 Metrix($W_1$)의 연산은 one hot vector의 index 부분과 그 index와 일치하는 Metrix의 column vector를 가져온 것과 동일하다. -> 즉 오른쪽 그림에서 파란색 부분의 유사도는 크게 만들어주고 흰색 부분의 유사도는 낮게 만들어주는 방향으로 학습이 진행된다.
- https://ronxin.github.io/wevi/ 참고
- window size에 따라 학습 데이터가 결정된다. window 사이즈가 3이라고 하면
- 이렇게 학습된 Word2Vec은 word간의 의미론적 관계를 잘 표현한다. ex) Korean Word2Vec,
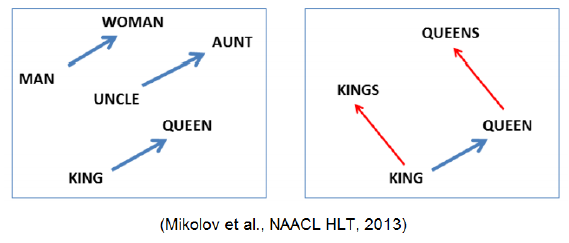
- Intrusion Detection(문장 내에서 가장 의미가 안 어울리는 단어를 찾는 작업)에서도 Word2Vec이 사용된다. 각 단어와 다른 모든 단어 사이의 평균 거리를 구하고 그 중 가장 큰 값을 가지는 단어
- GloVe
- 입력 / 출력 단어에 대해서 한 window 내에서 두 단어가 얼마나 동시에 등장했는지를 사전에 계산 -> Word2Vec에서의 중복된 계산을 줄여주는 효과
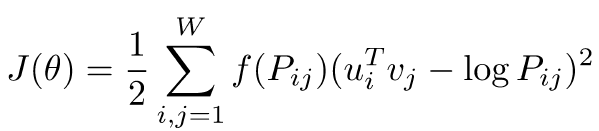
- 입력 / 출력 단어에 대해서 한 window 내에서 두 단어가 얼마나 동시에 등장했는지를 사전에 계산 -> Word2Vec에서의 중복된 계산을 줄여주는 효과
2. 새로 알게된 내용 / 고민한 내용 (강의, 과제, 퀴즈)
- 실습코드 : 1_naive_bayes
from konlpy import tag를 통해 다양한 tokenizer를 불러올 수 있다.- Okt tokenizer를 사용하기 위해서는 자바를 설치해야 한다.(Aistages 서버)
- Okt().morphs를 이용해 한국어를 형태소 별로 tokenizing 시킬 수 있다.
- tokenized된 data를 이용해 단어별 클래스에 따른 확률을 계산했다.(Laplace Smoothing을 적용)
- 실습코드 : 2_word2vec
- CBOW(Continuous Bag of Words)는 주변의 단어로 중심 단어를 예측하는 방식
- 실제 pad token을 맨 앞, 맨 뒤에 추가해서 context word를 추가한다.
- nn.Embedding과 nn.Linear의 차이는 sparse라는 인자에서 나타나는데 질문 게시판의 내용을 살펴보면 다음과 같다.
nn.Linear처럼 matmul operation으로 단어 vector가져오는 것은 비효율적이기 때문에 nn.Embedding을 사용한다. Input이 one-hot vector가 아닌 index 기반이기 때문에
sparse=True인자를 이용해 weight matrix에서 특정 열 벡터만 가져와서 계산할 수 있다. - sparse gradient를 제공해주는 optimizer는 제한적(SGD, SparseAdam, Adagrad)이기 때문에 사용에 주의해야 한다.
- Word2Vec에서 사전 내에 단어가 존재하지 않는 경우를 Out-Of-Vocabulary(OOV)문제라고 한다.
주로 unknown token을 추가하여 [unk] 등의 특수 토큰으로 대체하여 학습을 진행한다. padding을 위한 토근([pad] 토큰)도 추가하기도 한다.
- Skip-Gram은 중심 단어를 통해 주변 단어를 예측하는 방식
- Skip-Gram은 중심 단어가 window_size * 2 만큼 추가로 학습하게 된다.
- 그렇기 때문에 CBOW보다 Skip-Gram의 성능이 더 좋다.
- CBOW(Continuous Bag of Words)는 주변의 단어로 중심 단어를 예측하는 방식
- 필수과제 1 : Data Preprocessing
- spacy를 로컬에 설치하여 spacy.load(‘en_core_web_sm’) 모델 사용
nlp = spacy.load('en_core_web_sm') text = nlp('Naver Connect and Upstage Boostcamp') -------------------------------------------------- text >> # Naver Connect and Upstage Boostcamp [token for token in text] >> # [Naver, Connect, and, Upstage, Boostcamp] [token.text for token in text] >> # ['Naver', 'Connect', 'and', 'Upstage', 'Boostcamp'] - token을 출력하는 것과 token.text를 출력하는 것은 다르다.
- spacy.lang.en.stop_words.STOP_WORDS을 통해 불용어를 가져올 수 있다. ex) ‘s, regarding, nevertheless 등등
- Lemmatization(표제어 추출)과 Stemming(어간 추출)의 차이
Lemmatization은 기본 사전형 단어를 추출하고(are, is -> be) Stemming은 단순히 어간을 추출하는 것이다.(단어 사전에 존재하지 않는 단어일 수도 있다)
- tokenize한 token은 lemma_, is_punct(문장 부호인지), is_space, shape_(단어모양 Iron -> Xxxx), is_stop(불용어인지) 등의 함수를 사용할 수 있다.
- mecab을 이용해 한국어 형태소 분리
- spacy를 로컬에 설치하여 spacy.load(‘en_core_web_sm’) 모델 사용
3. 참고할 만한 자료
- 부스트코스 제공 자료
- 슬랭 공유 자료 및 참고 자료
4. 피어세션
- 협업툴 상의 -> 노션 !
- 모더레이터 역할 설정
- Ground rule 설정
- To Do List 작성
- 자세한 내용은 Peer Session 참조
Day 2
- 학습 강의 : Part 2 - RNN, LSTM, and GRU 3강, 4강
- 과제 : [필수과제 2] RNN-based Language Model
1. 강의 복습
NLP
3강 : Recurrent Neural Network and Language Modeling
- 기본적인 RNN 구조는 다음과 같다.
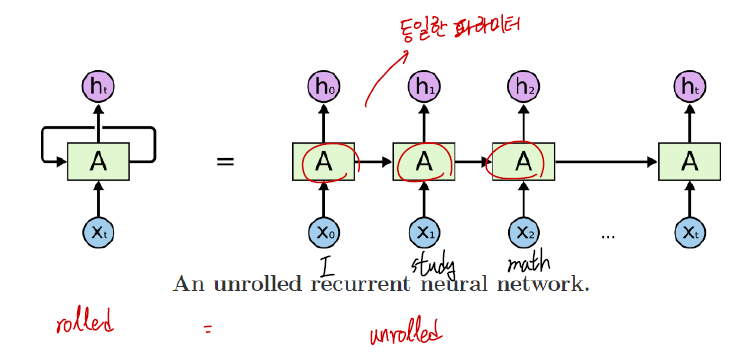
- 시퀀스 데이터가 입력값으로 들어간다.(I study math)
- RNN의 hidden state는 $h_{t}=f_{W}\left(h_{t-1}, x_{t}\right)$ 로 계산할 수 있다.
- $h_{t-1}$ : 이전 상태의 hidden state
- $x_t$ : Input vector
- $h_t$ : 현재 시점의 hidden state
- $f_W$ : $W$라는 linear matrix와 같이 연산하는 RNN 함수
- $y_t$ : 매 순간 계산하거나 마지막에서만 계산할 수 있다.
- 매 순간 적용되는 Linear matrix($W$)는 동일하다.
- RNN의 연산 과정은 다음과 같다.
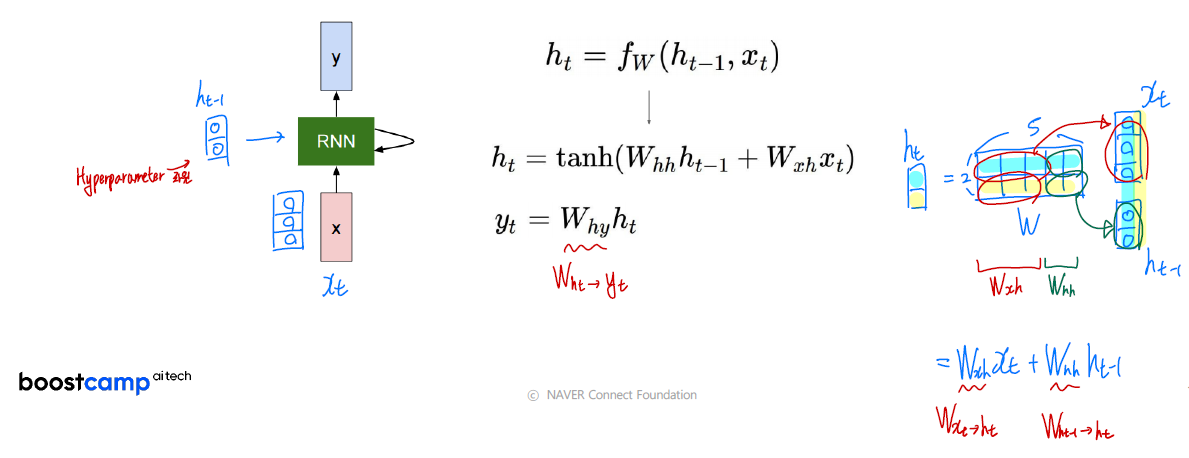
- 전체 $W$를 $W_{xh}$와 $W_{hh}$로 나누어서 생각할 수 있다.
- hidden state의 차원은 Hyperparameter로 직접 설정해야 한다.
- RNN의 종류에는 대표적으로 5가지의 경우가 있다.
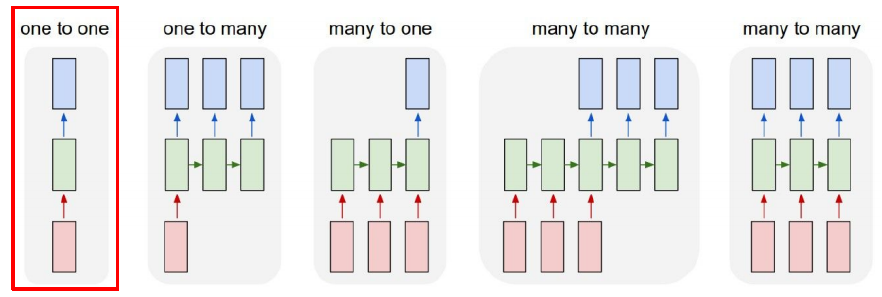
- One-to-one : 기본적인 Standard Neural Networks를 의미한다.
- One-to-many : Image가 들어가서 text가 나오는 것으로 생각할 수 있다.(Image Captioning)
- Many-to-one : Sentiment Classification 혹은 감정 분석으로 단어가 들어갔을 때 부정인지 긍정인지 분류해주는 task를 예로 들 수 있다.
- Many-to-many : 문장을 다 읽고 난 후 출력이 나오는 경우 ex) Machine Translation / 단어가 들어올 때마다 출력이 나오는 경우 ex) POS tagging
- Charater-level Language Model
- 단어가 주어졌을 때 중복되는 문자를 제거하여 Vocab을 만들고 각 문자를 학습시켜 다음 문자를 예측할 수 있도록 해야한다. -> h, e, l, l이 들어가면 e, l, l, o가 나올 수 있도록 !
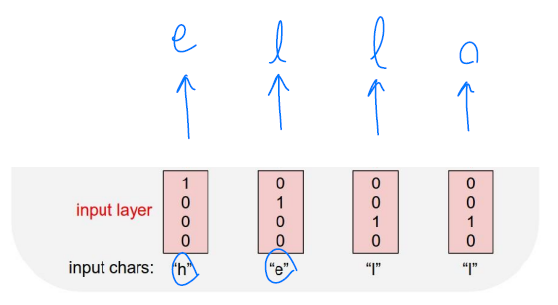
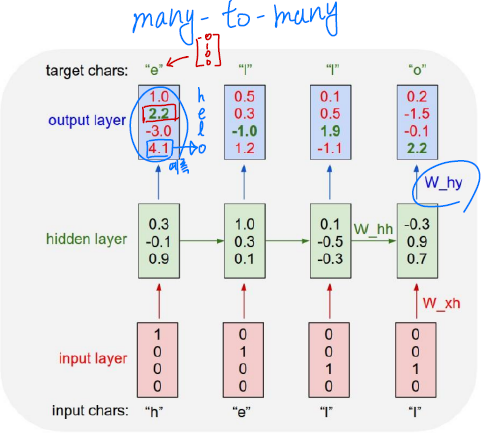
- 위 경우에는 h가 입력으로 들어갔을 때 실제 출력은 “o”이지만 원하는 target은 “e”이다. 이 경우 출력값과 타켓값을 줄이는 방향으로 학습이 진행된다.
- 추론을 할 때에는 한 문자가 들어가고 그 문자에 대한 출력이 다음 입력값으로 들어가는 형태이다.
- 단어가 주어졌을 때 중복되는 문자를 제거하여 Vocab을 만들고 각 문자를 학습시켜 다음 문자를 예측할 수 있도록 해야한다. -> h, e, l, l이 들어가면 e, l, l, o가 나올 수 있도록 !
- BPTT : RNN 모델에 입력되는 Sequence가 길어질 수록 BPTT를 할 때에 많은 GPU 리소스를 사용하게 된다. 이를 해결하기 위해 sequence를 여러 chunk로 나누어서 BPTT를 진행한다.(Trucated BPTT)
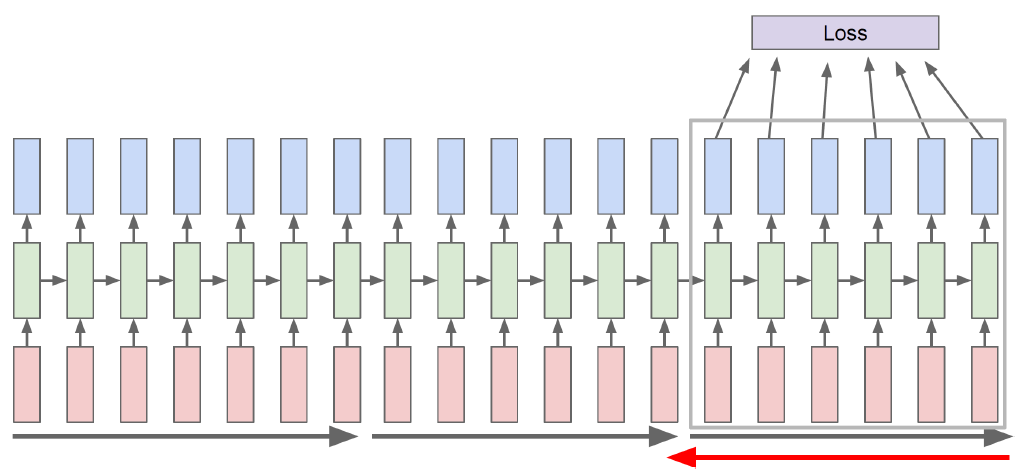
- hidden state의 특정 차원을 cell이라고 하고 이 cell을 고정시켰을 때 추후 결과를 살펴보면 고정 시킨 cell이 어떤 정보를 가지고 있는지 알 수 있다.(역추적)
- RNN은 BPTT 과정에서 gradient가 vanishing / exploding 하는 경우가 발생할 수 있다. 이를 해결하기 위해 LSTM, GRU를 사용한다. ex) RNN / LSTM 비교
4강 : LSTM and GRU
- LSTM은 Cell state를 추가하여 기존의 RNN의 long-term dependency 문제를 해결했다.
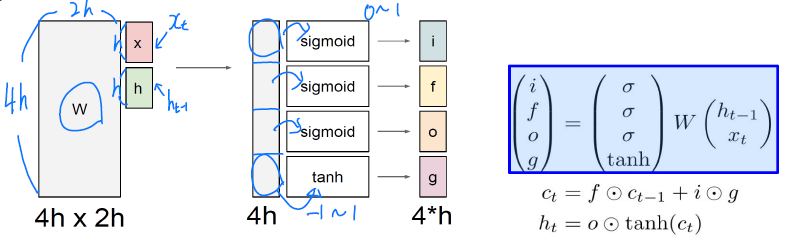
- i : Input gate
- f : Forget gate
- o : Output gate
- g : Gate gate
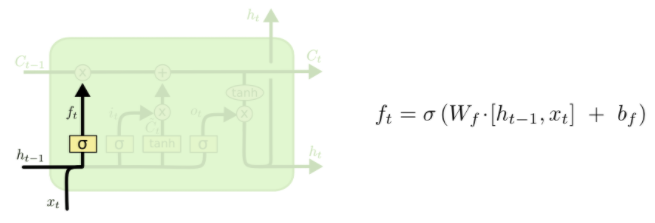
- 이전 hidden state와 현재 입력 $x_t$와 선형 변환을 하고 시그모이드 함수를 씌운 것이 f가 되고 이 값이 $C_{t-1}$과 곱해진다. 이는 이전 Cell state의 정보 중 특정 비율만큼만 취한다는 의미이다.
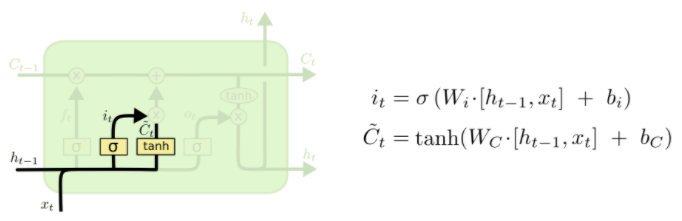
- $\widetilde{C}_{t}$는 $tanh$을 취했으므로 -1 ~ 1의 값을 가진다.
- $\widetilde{C}{t}$에 $i$를 곱해주는 이유는 $\widetilde{C}{t}$에서 한 번 선형 변환으로는 $C_{t-1}$에 더해줄 정보를 얻는 것이 힘들기 때문이다.
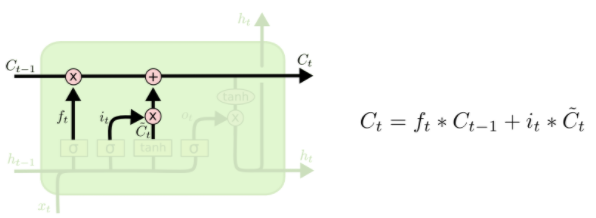
- 결국 forget gate를 통해 구한 이전 cell state + Input gate와 Gate gate를 통해 구한$\widetilde{C}_{t}$를 통해 현재 cell state($C_t$)를 계산한다.
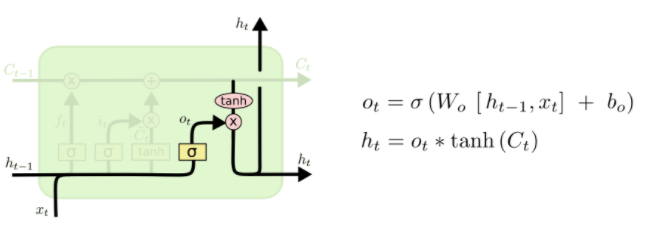
- 최종적으로 구한 $C_t$에 $tanh$을 취하고 $o_t$(0~1의 값)를 곱함으로 적절한 비율만큼 정보를 뽑아내서 $h_t$를 구성할 수 있다.
- 요약해보면 $C_t$는 기억해야할 필요가 있는 모든 정보를 담고 있는 벡터이고 $h_t$는 현재 시점에서 예측값에 직접적으로 필요한 정보만을 담고 있는 벡터로 해석할 수 있다. 즉, $C_t$에서 원하는 정보만을 filtering 한 것이다.
- Gated Recurrent Unit(GRU)는 LSTM에서 Cell state를 없애고 hidden state만 이용했다.
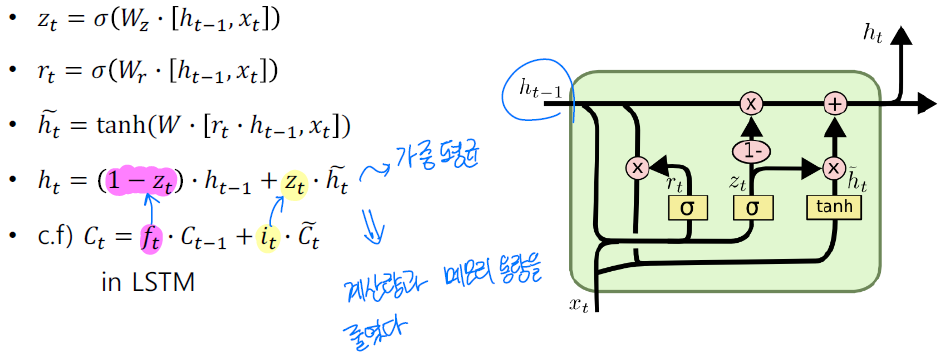
- 결국 LSTM에서 cell state역할을 hidden state가 하게 되고 현재 시점의 hidden state는 가중 평균을 통해 구하게 된다 -> 독립적인 두 개의 게이트($f_t$, $i_t$)에서 하나의 게이트($z_t$)로 줄였다.
- LSTM에 비해 성능은 크게 차이나지 않지만 계산량과 메모리 사용량을 줄였다는 장점이 있다.
- LSTM, GRU의 Backpropagation 과정에서는 덧셈의 연산이 존재하기 때문에 RNN과 비교하여 gradient가 vanishing / exploding하는 경우를 없앨 수 있다.
2. 새로 알게된 내용 / 고민한 내용 (강의, 과제, 퀴즈)
- 실습 코드 : 3_basic_rnn
- pytorch.nn.RNN은 기본적으로
input_size,hidden_size,num_layers,bidirectional값을 인자로 받는다. - Bidirectional RNN
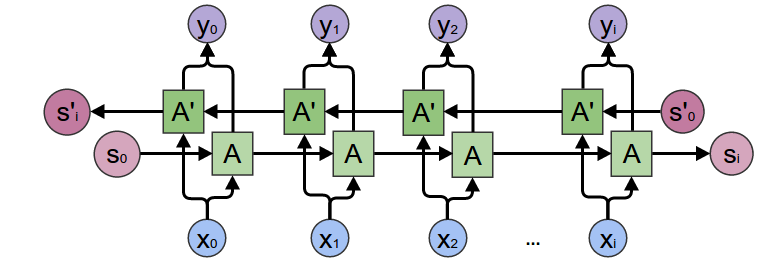
- 위 방법으로 생성한 rnn 모듈의 Input은
batch_first = False가 default이고 이 때 ($L, N, H_{in}$)으로 입력받는다. ($L$ : sequence length, $N$ : batch size) - rnn 모델의 출력값은 각 timestep의 모든 hidden states, 마지막 hidden state 이다. hidden states의 크기는
(seq_len, batch, num_directions * hidden_size)이고 마지막 hidden state의 크기는(num_layers * num_directions, batch, hidden_size)이다. - pack_padded_sequence를 이용해 불필요한 연산을 제거할 수 있다.
- packing한 것을 풀어줄 때에는 pad_packed_sequence을 이용한다.
- pytorch.nn.RNN은 기본적으로
- 실습 코드 : 4_fancy_rnn
- LSTM은 h_0 뿐만 아니라 cell state를 의미하는 c_0도 함께 필요하다. 두 값은 튜플 형태로 묶여서 들어간다.
packed_outputs, (h_n, c_n) = lstm(packed_batch, (h_0, c_0)) - Teacher forcing 없이 이전의 결과값을 사용하는 방식을 이해
batch에서 가장 처음 입력값들만 가져오고 그 이후에는 출력값을 사용
- Bidirectional RNN에서는 output과 h_n을 reshape함으로써 forward와 backward를 구분한다. 기존
out shape = (batch, seq_len, num_directions * hidden_size)에서out.view(seq_len, batch, num_directions, hidden_size)로,h_n shape = (num_layers * num_directions, batch, hidden_size)에서h_n.view(num_layers, num_directions, batch, hidden_size)로 reshape해준 후 각각의 hidden state를 추출할 수 있다.(num_directions에서 forward는 0, backward는 1이다.)
- LSTM은 h_0 뿐만 아니라 cell state를 의미하는 c_0도 함께 필요하다. 두 값은 튜플 형태로 묶여서 들어간다.
- 필수과제 2 : RNN-based Language Model
- nn.RNN에는 nonlinearity 인자가 존재한다.
default : tanh이고relu도 가능하다. nn.init.uniform_함수를 통해 Weight을 초기화할 수 있다.- torch.contiguous()를 통해 torch.tensor를 transpose한 후에도 주소의 연속성을 가질 수 있도록 한다. 자세한 내용은 블로그, 페이스북 참고
- embedding vector와 decoding vector의 차원을 살펴보면서 Text의 차원에 대한 감을 익혔다.
- 간단하게 말해서 [35, 20, 200] 차원의 벡터가 RNN의 입력으로 주어진다면 이는 20개의 문장이 존재하고 문장 속에 35개의 squence가 입력이 되고 이 때 각 단어의 입력은 200차원의 one hot vector(또는 nn.embedding layer를 통과한 vector)이다.(batch size : 20)
- torch.multinomial() 함수를 통해 확률 기반의 샘플링을 할 수 있다. 참고 블로그
- nn.RNN에는 nonlinearity 인자가 존재한다.
3. 참고할 만한 자료
- 부스트코스 제공 자료
- 슬랭 공유 자료 및 참고 자료
4. 피어세션
- 정유석 캠퍼님의 당일 강의 요약 발표
- 실습 코드 리뷰
- TMI 이야기(기억에 남는 여행지)
- 자세한 내용은 Peer Session 참조
Day 3
- 학습 강의 : Part 3 - Seq2seq with Attention, Beam Search and BLEU Score 5강
- 과제 : [필수과제 3] Subword-level Language Model
1. 강의 복습
NLP
5강 : Sequence to Sequence with Attention
- Seq2seq 모델은 Encoder와 Decoder로 이루어져 있고 파라미터 값을 공유하지 않는다.
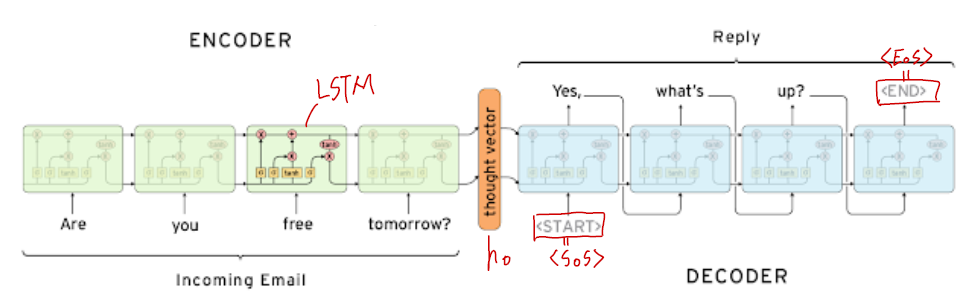
- Encoder의 마지막 step의 hidden state vector는 그동안 들어온 입력값에 대한 정보를 가지고 있다. 이 정보는 Decoder로 전달돼 가장 초기 hidden state vector($h_0$)가 된다.
- Decoder의 시작토큰으로
<SoS>를 넣어주고 종료토큰으로<EoS>를 넣어준다. - 일반적인 Seq2seq 모델의 문제점은 hidden state의 고정된 차원으로 인해 모든 정보를 담는 것이 어렵고 그로 인해 가장 초기에 입력된 값의 정보가 변질, 소실될 우려가 있다는 것이다.
- 이를 해결한 것이 Attention 모듈이다.
- Attention 모듈은 마지막 hidden state vector 뿐만 아니라 모든 hidden state vector를 통해 정보를 얻는다. ex) 번역 예시
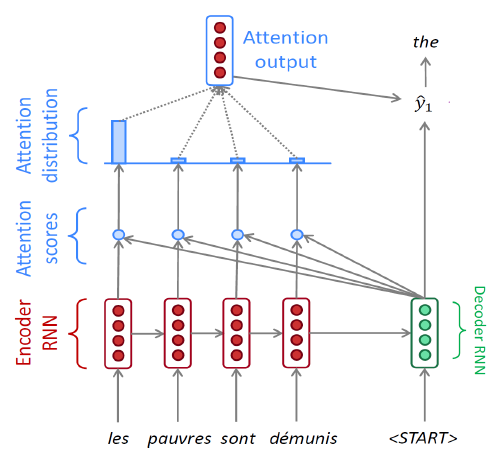
- Decoder는 Encoder의 마지막 hidden state vector와 start token의 embedding vector를 입력으로 해서 새로운 hidden state vector($h_1$)를 생성한다.
- Encoder의 각 sequence마다 hidden state vector가 존재하고 이 vector들과 Decoder의 $h_1$과 각각 내적하여 Attention score를 구한다.
- score 값들을 softmax를 통과시키면 확률값을 가지고 이는 Encoder hidden state vector의 가중치 역할을 히게 되고 Attention vector라고 한다.
- 결국 Decoder의 $h_1$과 Attention output vector가 합쳐져서 최종 출력값을 예측한다.
- Decoder의 timestep에 따라 다른 hidden state vector를 통해 Attention 모듈을 계산하게 된다.
- Decoder의 hidden state vector는 output layer의 입력으로 사용됨과 동시에 Attention 모듈의 가중치를 결정해주는 역할을 한다.(필요한 정보를 취사선택)
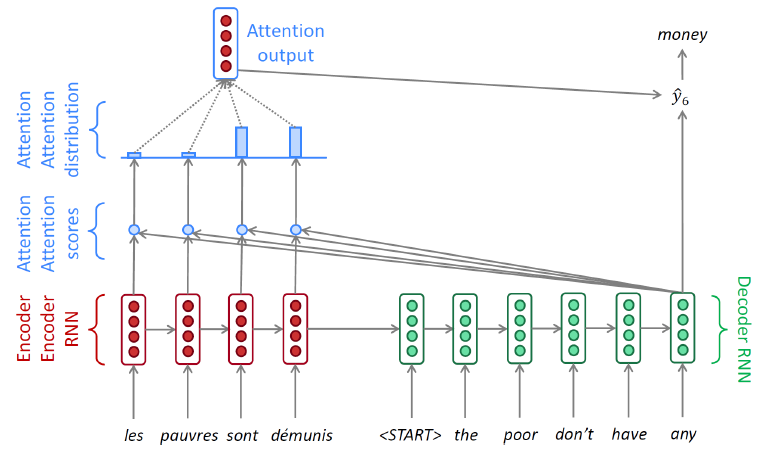
- 위 과정에서 학습시킬 때 입력값으로 이전 출력값이 아닌 GT(Ground Truth)를 넣어주는 것을 Teacher forcing이라고 한다.
- Teacher forcing을 통해 학습시키면 학습 속도가 빠르게 진행된다는 장점이 있지만 실제 추론 과정과 다르기 때문에 괴리가 생긴다.
- 때문에 초반에는 Teacher forcing을 통해 학습시키고 어느정도 학습이 진행된 후에는 이전 예측값을 다음 timestep의 입력값으로 넣어주는 방식으로 학습을 진행한다.
- Encoder의 hidden state vector들과 Decoder의 hidden state vector 간의 유사도를 구하는 방식은 내적뿐만 아니라 generalized dot product, concat 방식 등이 있다.
\(\operatorname{score}\left(\boldsymbol{h}_{t}, \overline{\boldsymbol{h}}_{s}\right)= \begin{cases}\boldsymbol{h}_{t}^{\top} \overline{\boldsymbol{h}}_{s} & \text { dot } \\ \boldsymbol{h}_{t}^{\top} \boldsymbol{W}_{a} \overline{\boldsymbol{h}}_{s} & \text { general } \\ \boldsymbol{v}_{a}^{\top} \tanh \left(\boldsymbol{W}_{\boldsymbol{a}}\left[\boldsymbol{h}_{t} ; \overline{\boldsymbol{h}}_{s}\right]\right) & \text { concat }\end{cases}\)
- generalized dot product는 행렬을 이용해 서로 다른 차원에서 가중치를 전달해줄 수 있다. 또한 학습 가능한 파라미터가 존재하게 되어 최적화가 가능하다.
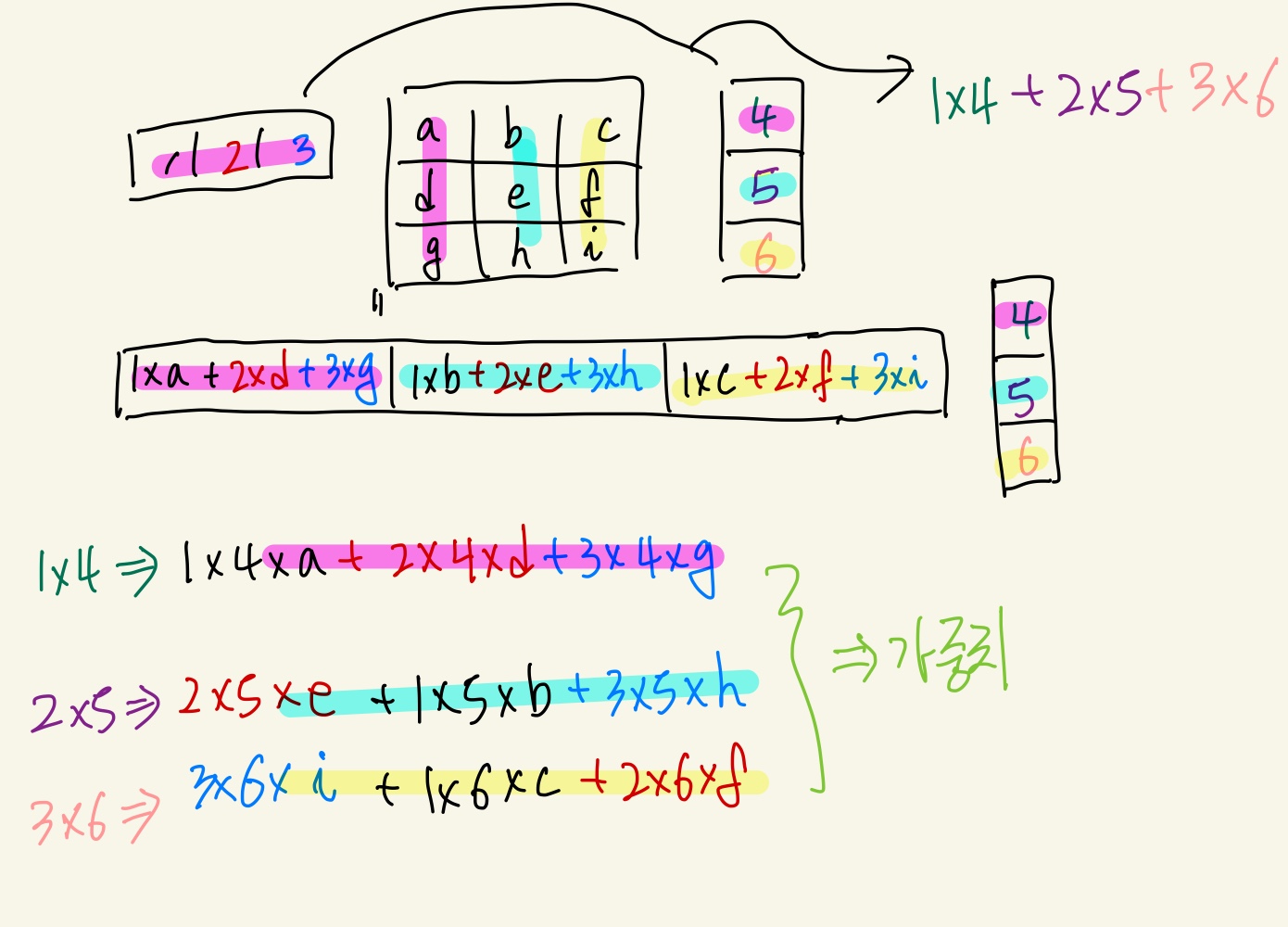
- concat으로 구성하게 되면 layer를 이용하기 때문에 Attention score를 구할 때에도 학습 가능한 파라미터가 존재할 수 있게 된다. -> 최적화가 가능하다.
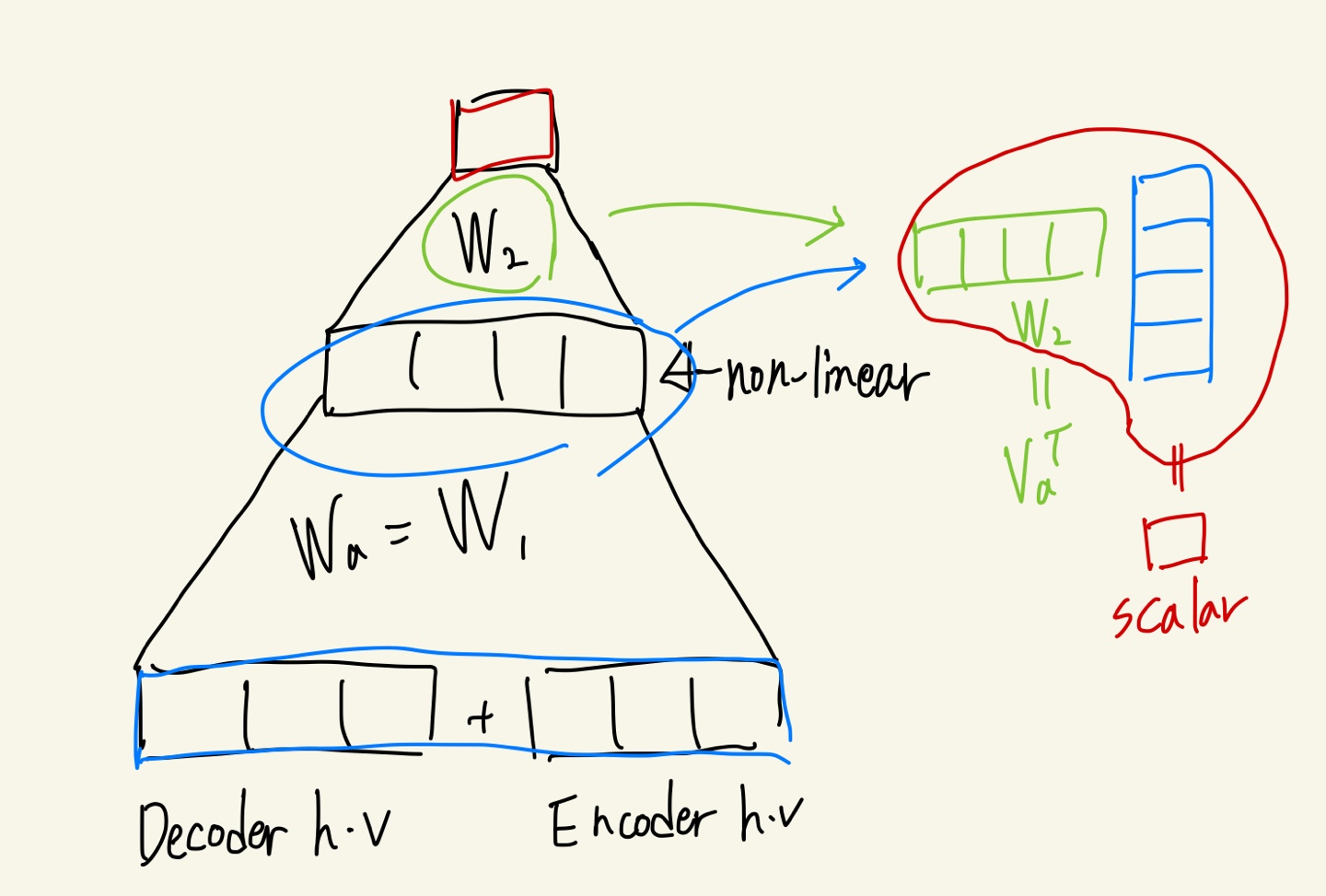
- generalized dot product는 행렬을 이용해 서로 다른 차원에서 가중치를 전달해줄 수 있다. 또한 학습 가능한 파라미터가 존재하게 되어 최적화가 가능하다.
2. 새로 알게된 내용 / 고민한 내용 (강의, 과제, 퀴즈)
- 실습 코드 : 5_seq2seq
- bidirectional RNN 형태의 encoder의 동작 원리를 파악했다.
- teacher forcing과 일반 학습의 차이를 이해했고 코드로 어떻게 적용이 되는지 확인했다.
- 필수과제 3 : Subword-level Language Model
from transformers import BertTokenizer을 통해 Bert 모델에서 사용한 subword tokenization algorithm을 이용할 수 있다.- torch.narrow(input, dim, start, length)으로 사용할 수 있다.
- torch.detach()는 기존 Tensor에서 gradient 전파가 안되는 텐서 생성하는 함수이다. 참고 블로그
3. 참고할 만한 자료
- 부스트코스 제공 자료
- 슬랭 공유 자료 및 참고 자료
4. 피어세션
- 당일 강의 요약 발표
- 실습 코드 및 과제 코드 리뷰
- 다음날 학습 목표 설정
- 자세한 내용은 Peer Session 참조
Day 4
- 학습 강의 : Part 3 - Seq2seq with Attention, Beam Search and BLEU Score 6강
- 과제 : [필수과제 4] Preprocessing for NMT Model
1. 강의 복습
NLP
6강 : Beam Search and BLEU Score
- 자연어 생성 모델(Seq2seq with attention)에서 전체적인 문장을 고려하는 것이 아닌 현재 시점에서의 단어를 통해 다음 한 단어만을 예측하는 것을 Greedy decoding이라고 한다. -> 한 단어를 잘못 예측하게 되면 뒤에도 영향을 미칠 수 있고 또한 잘못 예측했다는 사실을 뒤에 파악해도 수정할 수가 없다.
- Exhaustive search는 모든 단어를 전부 고려해서 예측한다.
\(P(y \mid x)=P\left(y_{1} \mid x\right) P\left(y_{2} \mid y_{1}, x\right) \ldots P\left(y_{T} \mid y_{1}, \ldots, y_{T-1}, x\right)=\prod_{1}^{T} P\left(y_{t} \mid y_{1}, \ldots, y_{t-1}, x\right)\)
- 위 식을 통해 단어를 생성한 후 다음 단어를 생성할 확률을 결합 확률로 계산하여 전체 확률을 계산한다. 모든 단어들의 조합을 살핀 후 가장 확률이 높은 문장을 채택
- 가능한 모든 경우를 전부 계산하기 때문에 매 Timestep마다 vocab size만큼의 연산이 필요하다. : $O(V^t)$
- 위 두 방식을 결합한 방법이 Beam search이다.
- 각 time step마다 사전에 정의한 k개의 가짓수만을 고려한다. 이 때 k는 beam size라고 한다.
- k개의 경우에 해당하는 output을 hypothesis라고 한다.
- $\operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\log P_{L M}\left(y_{1}, \ldots, y_{t} \mid x\right)=\sum_{i=1}^{t} \log P_{L M}\left(y_{i} \mid y_{1}, \ldots, y_{i-1}, x\right)$
- Beam search가 최상의 결과를 의미하는 것은 아니다. 하지만 Exhaustive search에 비해 훨씬 효율적이기 때문에 많이 사용된다.
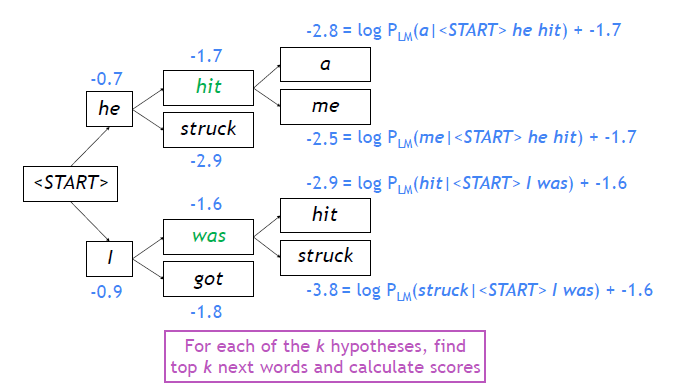
- 위와 같은 방식으로 그 때마다 k개의 후보만 선택해서 최종 확률을 계산한다.
- eos 가 들어옴으로써 hypothesis를 생성하게 된다. 이는 임시 메모리 공간에 저장된다.
- 사전에 지정한 Timestep까지만 계산하게 하거나 생성할 hypothesis의 개수를 지정함으로써 종료시킨다.
- 길이가 길어질수록 확률값이 더 작아지게 되므로 이는 단어의 개수로 Normalize 해줌으로써 해결한다.
- $\operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\frac{1}{t} \sum_{i=1}^{t} \log P_{L M}\left(y_{i} \mid y_{1}, \ldots, y_{i-1}, x\right)$
- I love you : target / Oh, I love you : prediction이라면 timestep끼리 정확도를 측정하게 된다면 0%가 나올 수 있다. 그렇기 때문에 고정된 시점이 아닌 전체 sequence를 보고 평가해야 한다.
- 이를 해결하기 위한 지표로 precision과 recall을 사용한다.

- precision은 정밀도를 의미하는 것으로 예측한 단어들 중 정확히 예측한 것의 개수를 세서 계산한다.
- recall은 재현율을 의미하는 것으로 타켓값(Reference)에 존재하는 단어들 중 정확히 예측한 것의 개수를 계산한다.
- precision은 결국 검색 결과로 나온 것들에 대해 얼마나 부합하는지를 의미하는 것이고 recall은 검색 결과로 보이지 않는 것까지 포함하여 키워드에 부합하는 문서들을 얼마나 노출시켰는지를 의미하는 것으로 해석할 수 있다.
- precision과 recall값의 조화 평균이 F-measure가 된다(산술 평균 $\geq$ 기하평균 $\geq$ 조화평균). 즉, 낮은 수치에 더 많은 가중치를 부여하는 것이다.
- 위 방법에서 가장 문제되는 상황은 예측값이 타켓값과 같은 갯수의 단어를 출력했지만 그 순서가 어긋나있는 상황이다.
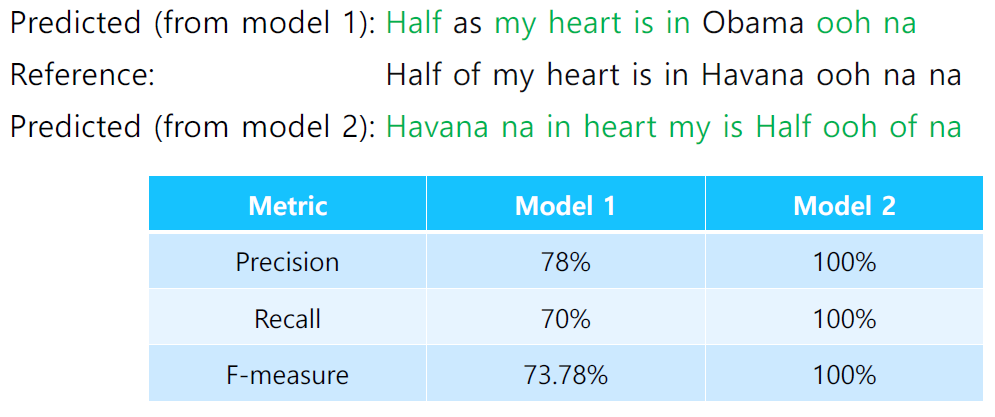
- 이처럼 문법적으로 옳지 않은 문장을 옳다고 판단할 수 있는 상황이 생긴다.
- 이를 해결하기 위한 방법으로 BLEU score를 사용한다.
- BLEU(BiLingual Evaluation Understudy) score
$ BLEU=\min \left(1, \frac{\text { length_of_prediction }}{\text { length_of_reference }}\right)\left(\prod_{i=1}^{4} \text { precision }_{i}\right)^{\frac{1}{4}} $
- n-gram이라는 단위로 측정을 한다. 연속된 n개의 단어가 일치하는지를 판단한다.
- brevity penality라는 항을 추가하여 recall을 역할을 대신한다. GT보다 짧게 예측한 거에 대한 penality를 주는 것이다.
- n-gram을 통해 예측한 값의 기하평균을 사용하는데 조화평균은 낮은 값에 지나친 가중치를 주기 때문이다.
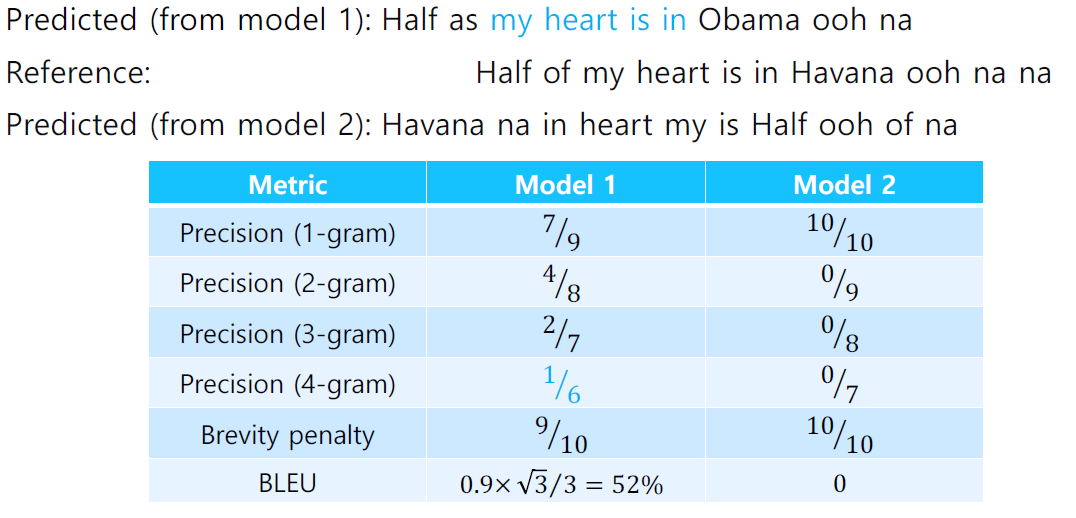
- BLEU score로 계산을 하면 순서를 고려해서 score를 매길 수 있다.
2. 새로 알게된 내용 / 고민한 내용 (강의, 과제, 퀴즈)
- 실습 코드 : 6_seq2seq_attn
- attention score와 value값을 구할 때 squeeze와 unsqueeze를 차원에 맞게 잘 써서 적용해야 한다. ```python query = decoder_hidden.squeeze(0) # (B, d_h) key = encoder_outputs.transpose(0, 1) # (B, S_L, d_h)
energy = torch.sum(torch.mul(key, query.unsqueeze(1)), dim=-1) # (B, S_L)
attn_scores = F.softmax(energy, dim=-1) # (B, S_L) attn_values = torch.sum(torch.mul(encoder_outputs.transpose(0, 1), attn_scores.unsqueeze(2)), dim=1) # (B, d_h) ```
- 특히 dot attention이 아니라 concat attention의 경우에는 torch.repeat함수를 이용해 차원을 확장해준 다음 encoder output과 concat을 적용한다.
decoder_hidden = decoder_hidden.transpose(0, 1).repeat(1, src_max_len, 1) # (1, B, d_h) -> (B, S_L, d_h)- x.repeat(1, src_max_len, 1)을 해석해보면 dim = 0은 1번, dim=1은 src_max_len번, dim=2는 1번 반복해서 텐서를 만들라는 의미이다.
- 필수과제4 : Preprocessing for NMT Model
3. 참고할 만한 자료
- 부스트코스 제공 자료
4. 피어세션
- 이종혁 캠퍼님의 당일 강의 요약 발표
- Attention 병목 현상 질의
- 다음날 학습 목표 설정
- 자세한 내용은 Peer Session 참조
Day 5
- 과제 : [선택과제 1] BERT Fine-tuning with transformers
1. 강의 복습
NLP
- 이번 주차 강의는 모두 들었기 때문에 다시 한 번 복습하는 시간을 가졌다.
2. 새로 알게된 내용 / 고민한 내용 (강의, 과제, 퀴즈)
- 선택과제1 : BERT Fine-tuning with transformers
3. 참고할 만한 자료
- 부스트코스 제공 자료
4. 피어세션
- 팀회고 작성
- 팀 구성에 대한 이야기
- 자세한 내용은 Peer Session 참조
주간 회고
-
이번주에 새로운 팀원들을 만나 Level 2 Ustage를 시작했다. 피어세션에서 새로운 피어들과 많은 이야기를 했다. 이야기를 들으면서 반성을 많이 했다. 나도 많이 하고 있다고 생각했지만 나보다 훨씬 잘하는 사람도 있고 그럼에도 더 많이 공부하는 사람이 있었다. “얼마나 더 노력해야 하나” 라는 생각도 들고 “이것도 부족하나” 라는 생각도 들어서 솔직히 많이 힘들었다.
-
반성과 자책을 많이하면서 공부에 집중하지 못했던 것 같다. 잘하고 있는지 의문도 생기고 다른 사람 이야기를 들으면서 내가 하고 있는 건 많이 부족하다는 생각도 들었다. 충분히 많이 하고 있다고 생각했는데 해야할 건 너무 많고 그래서 그 사이의 괴리가 생겨서 정말 막막했다. 지금도 막막한 심정이긴 하지만 그냥 부족함을 인정하고 천천히 해야할 것 같다.(
그래야 버티니깐..ㅠ) -
이번 주가 지금까지 보낸 부스트캠프 중 가장 집중하지 못한 주였던 것 같다. 월요일부터는 다시 마음 잡고 열심히 해야겠다. 실습 코드와 과제 코드는 clone coding으로 직접 구현하면서 이해하는 게 많은 도움이 될 것 같다. 논문 스터디는 화, 수요일에 정리해서 목요일날 발표 준비를 해야한다. 시각화 강의는 많이 밀렸지만 추석을 이용해 해결하고 또한 2주차 강의 과제 코드 또한 추석 때 다시 한 번 구현해보면서 공부할 생각이다. 또한 Pstage 전까지 “딥러닝을 이용한 자연어 처리 입문”을 한 번 정독하는 것과 HugggingFace 튜툐리얼을 해보는 것이 목표이다.
-
힘들어도 포기하지 말고 열심히 하자. 버티다보면 러닝커브가 좋아지겠지!!